Новосибирский Государственный Технический Университет, Кафедра ПВТ, Группа ПММ-61
Студент Гладких Пётр
Преподаватель Маркова В.П.
Основным параметром классификации параллельных компьютеров является наличие общей (SMP – Symmetric MultiProcessor) или распределенной памяти (MPP – Massive Parallel Processor). Нечто среднее между SMP и MPP представляют собой NUMA –архитектуры (Non Uniform Memory Access), где память физически распределена, но логически общедоступна. Кластерные системы являются более дешевым вариантом MPP. При поддержке команд обработки векторных данных говорят о векторно-конвейерных процессорах, которые, в свою очередь могут объединяться в PVP-системы с использованием общей или распределенной памяти. Все большую популярность приобретают идеи комбинирования различных архитектур в одной системе и построения неоднородных систем.
При организациях распределенных вычислений в глобальных сетях говорят о мета-компьютерах, которые, строго говоря, не представляют собой параллельных архитектур. [1]
В данном обзоре дано описание архитектуры cc-NUMA которая представляет собой NUMA архитектуру с аппаратной поддержкой когерентности кэшей (Cache Coherent Non-Uniform Memory Access).
Для начала рассмотрим класс ВС с симметричной мультипроцессорной обработкой (SMP).
Требования технологичности заставляют разработчиков разрабатывать небольшое количество стандартных узлов (процессоры, коммутаторы и т.п.), из которых собирается вычислительная система. Наиболее сложны в разработке микропроцессоры, и по этой причине их стремятся сделать универсальными устройствами широкого применения, пригодными для использования в любых вычислительных устройствах.
Изначально выделялись классы симметричных и несимметричных мультипроцессорных архитектур. Под несимметричными архитектурами понимаются такие архитектуры, в которых существует множество типов процессорных устройств, которые выполняют различные функции. Симметричные мультипроцессорные архитектуры, это такие архитектуры, в которых все процессорные устройства являются одинаковыми, с одинаковыми, функциональными возможностями и находятся в равных условиях. В современных вычислительных системах общего применения практически всегда используются универсальные микропроцессоры, а под архитектурами SMP часто понимаются архитектуры с однородным доступом к памяти по общей шине (UMA – Uniform Memory Access).
UMA архитектура предполагает наличие одной (реже двух или более) общей шины к которой подключены несколько процессоров. Доступ к любому элементу данных происходит единообразно, и, поэтому, данная архитектура имеет название “единообразный доступ к памяти”. Недостатком такой архитектуры является очень плохая масштабируемость, при увеличении числа процессоров прирост производительности уменьшается, так как увеличиваются времена ожидания для доступа к общей шине. Практически, ВС с такой архитектурой не содержат более 32 процессоров. Увеличение задержек объясняется тем, что одновременно с шиной может работать только один процессор. Если некоторый процессор занял шину для какой-либо операции, например, для чтения из памяти, другие процессоры должны ожидать своей очереди. Один из приёмов, позволяющих ослабить этот недостаток – использование кэшей, находящихся между процессором и шиной. Кэш позволяет не занимать шину, если необходимые данные уже находятся в нём. Но здесь возникает другая задача: необходимо поддерживать идентичность копий данных находящихся в этих кэшах. При увеличении числа процессоров эта задача становится всё более сложной. И для выполнения этой задачи часто используется дополнительное оборудование. Один из вариантов такой аппаратной поддержки синхронизации – специальная шина синхронизации кэшей (snoopy bus) предназначенная для передачи информации об изменениях в кэшированных данных.
При организации SMP системы основным основное внимание уделяется организации связей процессор – память, и именно они подвергаются кэшированию. Назовём эти связи вертикальными. К достоинствам данной архитектуры относятся: минимальные задержки при доступе к памяти (если число процессоров не слишком велико), пригодность ПО, созданного для однопроцессорных ВС.
Во время работы на UMA архитектурах исполняется только одна копия операционной системы при этом для получения прироста производительности по сравнению с однопроцессорной машиной, одновременно на разных процессорах должны выполняться различные процессы.
Противоположностью UMA архитектуре можно считать архитектуру MPP – вычислительная система с распределённой между процессорами памятью (distributed memory). Эта архитектура предполагает соединение полнофункциональных компьютеров быстрой сетью. Программы для таких архитектур обычно основываются на передаче сообщений. Достоинством данной архитектуры является практически неограниченная масштабируемость и дешевизна узлов данной системы, она может собираться даже из обычных персональных компьютеров. Преимуществом данного типа архитектур по сравнению с UMA является возможность одновременной работы всех коммуникационных устройств. Недостатки же следующие: так как используются сравнительно медленные соединения, то использование данной архитектуры эффективно только для задач, требующих небольшого числа пересылок.
Одним из основных противоречий при проектировании MPP компьютера является следующее: с одной стороны для наиболее эффективного выполнения пересылок между N процессорами, требуется наличие быстрых N*N связей между ними. Назовём эти связи горизонтальными. Но это число быстро растёт с увеличением числа процессоров. Кроме того, стоимость линии связи пропорциональна её скорости работы. Если же используется меньшее количество связей, то возникают проблемы, аналогичные тем, что существуют в UMA машинах.
Таким образом, две описанные выше архитектуры обладают своими собственными достоинствами. Естественно возникает желание объединить эти достоинства в одной архитектуре таким образом, чтобы иметь небольшие задержки при доступе к памяти и при этом иметь хорошие возможности масштабирования. Для достижения этой цели предложено множество архитектур. Рассмотрим одну из них: NUMA.
Архитектура NUMA предлагает следующий подход к созданию масштабируемых вычислительных систем. Для сохранения приемлемой стоимости вычислительной системы топология связей разбивается на несколько уровней. Каждый из уровней предоставляет соединения в группах с небольшим количеством узлов. Такие группы рассматриваются как единые узлы на более высоком уровне. На данный момент созданы ВС с двухуровневыми схемами связей. Подобная организация позволяет использовать быстродействующие соединения на каждом из уровней, а также даёт свободу выбора топологии связей в нём. Так, например, узлы могут быть соединены коммутатором “точка-точка” (crossbar), кольцом (МВС1000, NUMA-Q), двумерным тором (Convex Exemplar).
Неформальным обоснованием разбиения коммуникаций на уровни является то, что фрактальные структуры, которые, по сути, строятся при этом, обеспечивают небольшое число переходов между узлами сети при сравнительно небольшом числе связей.
Узлы NUMA архитектуры имеют собственную память и по этому признаку их можно отнести к классу MPP. В тоже время каждый узел может быть организован как UMA компьютер. Поэтому данную архитектуру можно считать наследницей двух рассмотренных ранее архитектур MPP и UMA.
Эта архитектура ориентирована на крупноблочное распараллеливание программ.
Ключевым понятием многопроцессорных архитектур является узел - вычислительная система, состоящая из одного или нескольких процессоров, имеющая оперативную память и систему ввода-вывода. Узел характеризуется тем, что на нем работает единственная копия операционной системы (ОС).
Вычислительная система данной архитектуры состоит из набора узлов (которые могут содержать один или несколько процессоров) которые соединены между собой коммутатором либо быстродействующей сетью. Таким образом, множество шин и линий передачи данных можно разделить на несколько классов в зависимости от их быстродействия, или, что тоже самое, в зависимости от их пропускной способности. Можно выделить такие классы:
Этим классам можно сопоставить множества реальных или воображаемых запоминающих устройств. Реальными являются запоминающие устройства узлов (кэш и основная память). А воображаемыми можно назвать запоминающие устройства других узлов, как они выглядят для данного узла. Таким образом, неоднородность доступа в данной архитектуре состоит в различии методов, используемых для доступа к некоторому элементу данных. Эти методы будут различаться в зависимости от того, находится этот элемент в локальной памяти данного узла или же он находится в памяти других узлов.
В целом доступ к данным в NUMA происходит через следующие элементы
В зависимости от архитектуры и операции данные проходят разные подмножества этих устройств. Например, в традиционной архитектуре NUMA не используется сетевой кэш.
Сегодня существует несколько различных архитектур (RMC, MPP, CC-NUMA и COMA), для которых характерен доступ к неоднородной памяти и, следовательно, применим термин "NUMA". Однако, все эти архитектуры принципиально различны. RMC- и MPP-системы содержат множество узлов, и их принадлежность к NUMA заключается в программно - реализованной когерентности между узлами. В CC-NUMA и СОМА когерентность реализована аппаратно и является внутриузловой. [2]
Организация соединений в NUMA предполагает различные пути доступа к различным участкам распределённой в системе памяти. Эти пути будут различаться в зависимости от того, находятся ли данные топологически близко (в текущем узле) либо на удалённом узле. Это различие и дало название архитектуре NUMA - “неоднородный доступ к памяти”. Так, например, если процессор запрашивает данные из текущего узла, то они сначала ищутся в локальном кэше процессора, а затем в локальной памяти данного узла. Если же данные находятся на другом узле, то они запрашиваются по сети.
В зависимости от пути доступа к элементу данных, время, затрачиваемое на эту операцию, может существенно различаться. Кроме того, в зависимости от реализации конкретная реализация NUMA может иметь больше или меньше черт архитектур UMA или MPP.
Рассмотрим одну из конкретизаций архитектуры NUMA cc-NUMA.
cc-NUMA – “неоднородный доступ к памяти с поддержкой когерентности кэшей”. Логически память NUMA системы представляется единым сплошным массивом, но распределена между узлами. Любые изменения сделанные каким-либо процессором в памяти становятся доступны всем процессорам благодаря механизму поддержания когерентности кэшей. Архитектура cc-NUMA предполагает кэширование как вертикальных (процессор - локальная память) так и горизонтальных (узел - узел) связей. Кэширование вертикальных связей позволяет организовать каждый узел как UMA компьютер, позволяя получить преимущества UMA архитектуры используя небольшое количество процессоров (обычно 2 или 4) над общей памятью и увеличивая тем самым производительность до 4 раз. В тоже время, возможность комбинирования в одной вычислительной системе множества узлов UMA данной архитектуры позволяет наращивать мощность, не увеличивая слишком количества процессоров в каждом узле. А это позволяет использовать преимущества UMA архитектур, и одновременно имея большое количество процессоров в одной вычислительной системе.
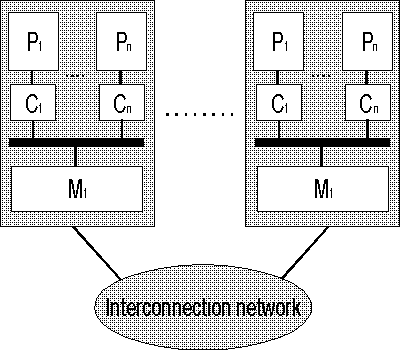
На рисунке ниже представлены различия между NUMA и cc-NUMA архитектурами:
Общая структура архитектуры NUMA
Общая структура архитектуры cc-NUMA.
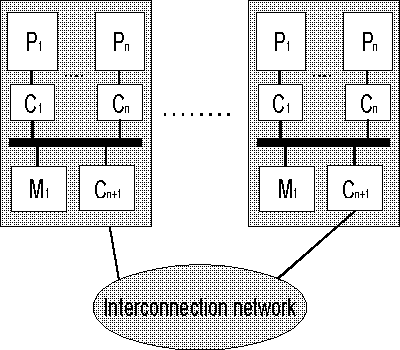
Обозначения: P – процессор, С – кэш, М – память, Interconnection network – соединяющая сеть.
В системе CC-NUMA физически распределенная память объединяется, как в любой другой SMP-архитектуре, в единый массив. Не происходит никакого копирования страниц или данных между ячейками памяти. Адресное пространство в данных архитектурах делится между узлами. Данные, хранящиеся в адресном пространстве некоторого узла, физически хранятся в этом же узле. Нет никакой программно - реализованной передачи сообщений. Существует просто одна карта памяти, с частями, физически связанными медным кабелем, и очень умные (в большей степени, чем объединительная плата) аппаратные средства. Аппаратно - реализованная кэш-когерентность означает, что не требуется какого-либо программного обеспечения для сохранения множества копий обновленных данных или для передачи их между множеством экземпляров ОС и приложений. Со всем этим справляется аппаратный уровень точно так же, как в любом SMP-узле, с одной копией ОС и несколькими процессорами. [1]
Программное обеспечение для NUMA архитектур не использует коммуникационные операции явно. Все процессоры разделяют общее адресное пространство. Копирование данных, из одного адреса в другой, может фактически повлечь пересылку данных из одного узла в другой, если целевой адрес принадлежит адресному диапазону другого узла. В этом состоит ещё одно сходство cc-NUMA и UMA архитектур, и эта особенность позволяет использовать в cc-NUMA программное обеспечение для UMA архитектур с незначительными изменениями.
С другой стороны, использование горизонтальных кэшей позволяет уменьшить среднее время доступа к удалённой памяти, так как принцип локальности, который делает использование кэширования эффективным, сохраняется для всех данных имеющихся в системе. Таким образом, если данные из удалённого узла уже находятся в кэше, то не требуется использовать для их доставки сравнительно медленное сетевое соединение. Наличие горизонтального кэша так же позволяет более эффективно проводить обновления данных, принадлежащих другим узлам, чем это было бы в случае использования основной памяти узла для хранения таких данных. Данное свойство даёт этой архитектуре преимущества в сравнении с традиционной MPP архитектурой, для которой время доступа к удалённым данным постоянно и не зависит от предыстории операций чтения/записи.
При использовании большого числа кэшей возникает та же проблема что и в архитектуре UMA: необходимо поддерживать актуальность кэшированных данных. Практически это означает, что изменение любой ячейки памяти, копия которой находится в некотором кэше, должно быть повторено для всех её копий. Учитывая, что число копий может быть велико, это становится сложной технической задачей.
Другими словами проблема поддержания когерентности в cc-NUMA возникает на разных уровнях: на уровне узла и на уровне коммуникационного слоя. Но, благодаря иерархичности организации коммуникаций, сложность (максимальное число копий некоторого объекта) на уровне узла невелика.
Стратегии поддержания актуальности копий могут различаться. Два наиболее распространённых подхода это использование передачи сообщений (message passing) и использование специальных сетевых соединений. В обоих случаях единицей данных может являться некоторый фрагмент памяти.
В одном случае, память разбивается на страницы длинной менее 4 Кб. Изменения данных в этом варианте распространяются по одной или более специальных шин, называемых “snoopy bus”.
В другом случае, единицей данных может являться элемент, выделенный динамически во время выполнения программы. В последнем случае схема поддержания актуальности копий называется “схемой каталога” (directory scheme).
Фактически сетевые соединения в ВС архитектуры cc-NUMA передают информацию об изменениях кэшированных данных или данных, запрошенных при кэш–промахах так как программное обеспечение явно не запрашивает коммуникационные операции.
Эта архитектура демонстрирует переход от шинно-ориентированной архитектуры сетей, к более общему виду коммуникационной сети. От простой (snoopy) схемы поддержания когерентности к схеме каталога (directory scheme).
Стоит сравнить эту архитектуру с архитектурой COMA. COMA или Cache-Only Memory Architecture - это архитектура, конкурирующая c СС-NUMA, спроектированная с аналогичными целями, но имеющая другую реализацию. Вместо того чтобы распределять части памяти и поддерживать их когерентность, как это делается в CC-NUMA, COMA-узел не имеет памяти, а только большие кэши (называемые attraction memories) в каждом обрабатывающем блоке - кводе (quad). В этой архитектурой предполагается отсутствия основной памяти в узлах. Для значений данных нет "домашних" ячеек памяти, в узле работает одна общая для всех кводов копия ОС, а когерентность в узле поддерживается специальным аппаратным соединением. Эта особенность компенсируется наличием в каждом узле большого по объёму кэша. Данная архитектура предъявляет более жёсткие ограничения на межузловые коммуникации, так как каждый кэш-промах требует обращение по сети к основной памяти за актуальными данными. Аппаратные средства COMA способны компенсировать недостатки алгоритмов ОС по распределению памяти и диспетчеризации. Однако для COMA требуется внесение изменений в подсистему виртуальной памяти ОС и заказные платы памяти дополнительно к плате кэш - когерентного соединения. [1]
Рассмотрим, как рассмотренные особенности проявляются в конкретных реализациях данной архитектуры.
Все CC-NUMA машины предназначены для одной цели: построить масштабируемый мультипроцессор с разделяемой памятью.
Основные различия у машин этого класса заключаются в способах поддержания когерентности кэшей в пределах всей вычислительной системы. Кроме того, различающим признаком является выбор коммуникационной сети для соединения процессоров.
Рассмотрим варианты, которые выбираются при создании вычислительной системы с данной архитектурой [3]:
Сложность узлов
Однопроцессорные
Кластерные (c одиночной шиной, c коммутатором)
Распределение основной памяти
По шинам, обслуживающим набор процессоров (см., например, Wisconsin Multicube)
По узлам
По кластерам
Схема поддержания актуальности кэшей
Следящий кэш (snoopy cache)
Следящий кэш и алгоритм каталога
Алгоритм каталога
Соединяющая сеть
Сеть шин
Полносвязная сеть (mesh)
Кольцо
Висконсинская архитектура Multicube является наиболее близким обобщением одиночного шинно-ориентированного компьютера. Она полностью полагается на snoopy протокол кэширования, но организованный в стиле схемы каталога. Milti-Multi Aquarius архитектура сочетает в себе snoopy протокол кэширования с directory организацией, но коммуникационная сеть полностью основана на идее разделяемой шины (shared multibus).
Как Висконсинская архитектура, так и архитектура Multi-Multi имеют узлы с единичными процессорами.
Узлы стэндфордской архитектуры Dash более сложны и являются основанными на одношинной архитектуре мультипроцессорами, названные кластерами. Кроме того, архитектура Dash включает snoopy протокол Dash с directory схемой. Snoopy схема поддерживает когерентность внутри кластера, а directory схема поддерживает когерентность между кластерами. В архитектуре Dash, directory протокол не зависит от типа коммуникационной сети. Поэтому для этой архитектуры можно использовать любой вид сети с малыми задержками.
Стэндфордская архитектура FLASH является дальнейшим развитием Dash той же самой группой разработчиков. Главной целью архитектуры FLASH было эффективное объединение разделяемой памяти с когерентным кэшем, и высокоскоростной передачей сообщений. Так как в архитектуре FLASH узлы уже однопроцессорные, то snoopy протокол кэширования не используется, и для поддержания когерентности и используется только directory схема.
Convex Exemplar является коммерчески доступной системой класса CC-NUMA, которая предоставляет масштабируемый интерфейс поддержания когерентности (Scalable Coherent Interface). Этот интерфейс позволяет поддерживать когерентность кэшей по всей системе по directory схеме.
Ниже приведён обзор и классификация различных типов архитектур:
Таблица 1.
Реализации и компьютерные архитектуры.
|
Кластеры |
NUMA |
Системы с большой шиной (UMA) |
|||
|
MPP |
RMC |
CC-NUMA |
COMA |
||
|
S5000 |
SP-2 Switch |
Sequent S5000 c SDI |
NUMA-QTM |
KSR |
Pyramid(r) Nile series |
|
HP T500 |
NCR Bynet |
DEC TruClaster |
DG CC:NUMA |
SUN S3.mp |
Sequent S5000 |
|
SPARGcenter Clusters |
Tandem ServerNet |
HP SPP1600 |
Stanford Flash |
HP T500 |
|
|
Pyramid |
MIT Alewife |
DEC TurboLaser |
|||
|
Clusters |
Sun S3.mp |
SPARCCenter 2000 SGI Challenge |
|||
|
Многоузловые |
Одноузловые |
||||
Рассмотрим подробнее три реализации архитектуры cc-NUMA.
В этой архитектуре используются горизонтальные и вертикальные шины, образующие двумерную решётку. Трёхмерное обобщение которой даст кубическую архитектуру. Главная память распределена по вертикальным шинам, и каждый блок памяти относится к одной из них (home column). Работа линейки процессоров на некоторой горизонтальной шине аналогична работе мультипроцессора с общей шиной. Сообщения об изменении данных распространяются по каждой шине в одном направлении, то есть все шины решётки - однонаправленные. Архитектура изображена ниже:
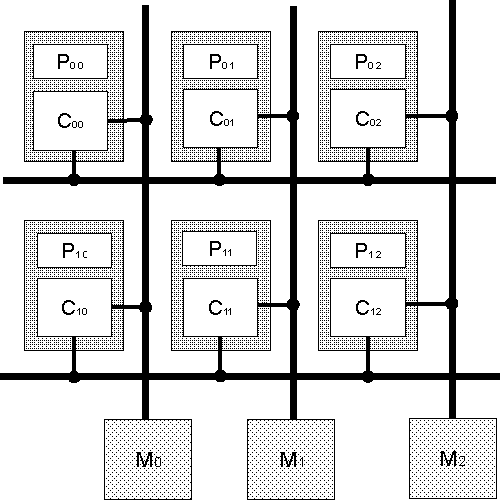
Где
Каждый процессор имеет обычный кэш для уменьшения задержек памяти и snoopy кэш, который следит за своей горизонтальной и вертикальной шиной для реализации протоколов обратной записи (write-back) и сброс при записи (write-invalidate). Заметим, что симметрия организации гиперкуба распространяет потоки данных в шинах единообразно по строкам и столбцам. Эта симметрия сильно уменьшает вероятность узких мест для коммуникаций.
Организация в виде решётки в случае кэш-промаха требует максимум вдвое большее число шинных операций по сравнению с одношинным мультикомпьютером. [2].
Опишем, в общих чертах алгоритм поддержания когерентности кэша (CC протокол) висконсинской архитектуры Multicube.
Определим:
Возможные состояния блоков в памяти
Каждый блок памяти может находиться в одном из двух состояний, в зависимости от которых, обрабатываются запросы к памяти на чтение/запись.
Возможные состояния блоков в кэшах
Блоки данных в некотором кэше могут находиться в трех локальных состояниях
Каждый контроллер кэша содержит специальную структуру данных, называемую строковой таблицей модификации (modified line table, MLT) эта таблица содержит адреса всех модифицированных блоков данных, присутствующих в кэшах в данной колонке процессоров. Нужно заметить, что все такие таблицы в данной колонке должны быть идентичными.
Кэш-контроллер может выдавать четыре типа команд поддержания целостности:
Определение переходов из состояния в состояние и путей передачи команд.
Здесь определены только механизмы выполнения команд READ и READ-MOD.
Запрос READ для блока данных, находящегося в модифицированном состоянии. Запрос READ выдан на горизонтальной шине контроллером, чья MLT содержит адрес X, содержащийся в C11, имеющий домашнюю колонку 2 как показано на рисунке ниже. В этом случае С01 принимает запрос и распространяет его по колонке, в которой все контроллеры переводят состояние X в немодифицированное. Одновременно, C11 принимает запрос и доставляет X. И окончательно, C11 передаёт X по вертикальной шине, где C01 принимает блок X и распространяет его по строке. Запрашивающий кэш C00 принимает X как и контроллер C02, находящийся в домашнем столбце, который записывает X обратно и переводя его в состояние "немодифицирован", выдавая команду Mem-Write(X, unmodified).
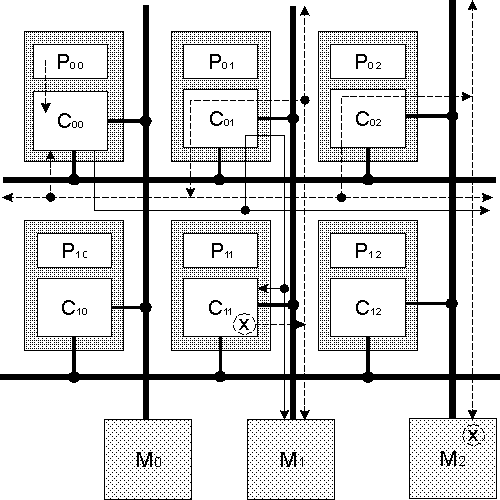
Запрос READ для блока данных, находящегося в немодифицированном состоянии. В этом случае контроллер C02, находящийся на домашней шине, принимает запрос. Если X имеет копию в C02 то она непосредственно посылается обратно в C00 по горизонтальной шине. Иначе, C02 передаёт запрос в память по вертикальной шине (колонке). При получении X из памяти по вертикальной шине, C02 передаёт X по строке в C00.
Запрос READ-MOD для блока данных, находящегося в модифицированном состоянии. После первых двух шинных операций (тех же что и в запросе READ) C11 принимает запрос, объявляет неверной копию X и передаёт это по строке. Здесь контроллер C10 принимает блок данных и распостраняет его по колонке. Окончательно C00 принимает X, сохраняет его в модифицированном состоянии. Как побочный эффект последних операций на колонке, все контроллеры 0 колонки добавляют X в MLT. Заметим, что главная память при этом не обновляется (так как используются write-back протоколы).
Запрос READ-MOD для блока данных, находящегося в немодифицированном состоянии. В этом случае контроллер из домашней колонки принимает запрос и перенаправляет его в главную память, которая направляет обратно запрос на обновление (invalidate request) для всех копий X. Каждый контроллер в колонке принимаетзапрс на обновление и рассылает его по соответствуюшей шине - строке. C02 рассылает запрос на обновление всех копий X, содержащихся в 0 строке. И окончательно C00 принимает копию X и рассылает команду поддержания целостности по своеё колонке, заставляя другие контроллеры записать в свои кэши адрес X в MLT.
Узлы Dash архитектуры являются одношинными мультипроцессорами, называемыми кластерами. Каждый кластер состоит из четырёх процессорных пар (процессор MIPS 3000 и процессор для операций с плавающей точкой R3010), интерфейса ввода-вывода, кэшей первого и второго уровня, части главной памяти а также схем для организации кластера и directory протокола.
Заметим, что память распределена между узлами Dash что снижает требования к пропускной способности коммуникационной сети. Кэши второго уровня с обратной записью ответствены за поддержание когерентности внутри кластера. Для этого применяется snoopy протокол. Память каталога реализует directory схему когерентности по всем кластерам. Коммуникационная сеть может быть любой сетью с малыми задержками и рассчитанной на архитектуры с передачей сообщений. В конкретном прототипе Dash использованы две параллельных сети (wormhole routed). Одна и сетей предназначена для передачи запросов, а другая - для ответов на сообщения.
Можно отметить, что за исключением кэшей и памяти каталога, архитектура Dash похожа на многие системы с передачей сообщений (message passing systems). Нововведением архитектуры Dash является распределённая реализация схема когерентности, основанная на каталогах (directory-based). Система памяти Dash разбита на четыре уровня:
уровень процессора (запрос к памяти удовлетворяется процессорным кэшем)
Наряду с реализацией модели "свободной" целостности (release consistency model), в архитектуре Dash применены различные оптимизации доступа к памяти. Так, например, в этой архитектуре применяются программно реализованные операции упреждающей выборки (prefecth operations). [2]
Основной целью разработки архитектуры Stanford FLASH являлась эффективная комбинация разделяемой памяти с когерентными кэшами и совершенной организации передачи сообщений. Такая организация выбрана для того что бы снизить затраты на оборудование и программное обеспечение, предоставив при этом высокую производительность. Основной элемент данной архитектуры это её узел. Он содержит высокопроизводительный микропроцессор (MIPS T5) с кэшами, часть главной памяти и микросхему MAGIC.
Структура машины FLASH
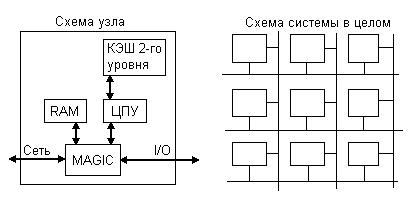
Сердце архитектуры FLASH это чип MAGIC, который содержит контроллер памяти, сетевой интерфейс, программируемый процессор протоколов и контроллер ввода-вывода.
Применённый протокол поддержания когерентности имеет два компонента:
Структура данных каталога основана на полудинамической схеме размещения указателя для поддержания списка процессоров разделяющих данный объект. Этот протокол очень похож на Dash протокол с главным отличием в сборе подтверждения об изменениях (invalidation acknowledgements). В то время как в Dash каждый кластер собирает свои собственные подтверждения, в FLASH они собираются домашним узлом данных (тем узлом, в котором они хранятся). [3]
Элементарным блоком платформы NUMA-Q (производитель – фирма Sequent) служит квод (NUMA-Q означает CC-NUMA с кводами), в котором объединены четыре процессора, блок разделяемой памяти и шина PCI с семью слотами. Несколько кводов могут быть соединены связями с аппаратно - реализованной кэш-когерентностью для формирования более крупного одиночного SMP-узла таким же образом, как процессорные платы добавляются к объединительной плате обычного SMP-узла с большой шиной.
Sequent рассматривает архитектуру NUMA-Q, как магистральную линию развития в будущем больших SMP-узлов, которая позволит преодолеть присущее SMP-платформам на основе общей шины ограничение в 32 процессора на узел и повысить возможности масштабирования систем SMP на порядок. Наиболее известную альтернативу традиционному подходу представляет аппаратно - реализованная кэш-когерентность на основе каталога. Специалисты Sequent пришли к заключению, что наилучшим вариантом является архитектура с кэш-когерентностью и неоднородной памятью, базирующейся на стандартизированном подходе SCI.
Квод NUMA-Q может быть единственным обрабатывающим элементом в системе. В этом случае сам квод является ее узлом. Если же система содержит несколько кводов, она все еще будет одноузловой, в ней со всеми кводами станет работать только одна копия ОС, и здесь квод уже не узел.
NUMA-Q-узел с тремя кводами и шиной IQ-Link.
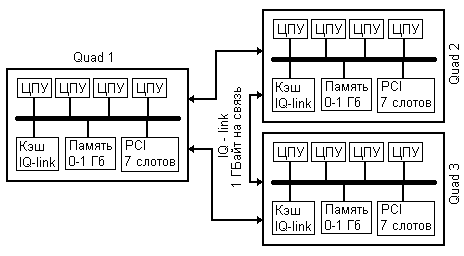
Кэш-когерентное соединение устанавливается между кводами и называется IQ-Link - это полностью аппаратное соединение, которое практически прозрачно для программ подобно обычному кэшу. Различие между SMP-узлом с объединительной платой и NUMA-Q-узлом с множеством кводов заключается в том, что соединение в системе NUMA-Q снимает ограничения одной объединительной платы и позволяет строить очень большие узлы с SMP подобной архитектурой. Резкое повышение масштабируемости достигается за счет того, что 12 процессорных блоков не устанавливаются на единую общую плату, а объединяются в группы - кводы, и между этими группами и памятью вставляются медные перемычки. IQ-Link поддерживает кэш-когерентность так же, как это делает объединительная плата SMP.
Системы с большими шинами проектировались для увеличения пропускной способности, но не снимали проблемы задержек. Используя короткие шины внутри каждого квода, можно достичь очень малых задержек для большинства операций доступа к памяти. Таким образом, IQ-Link позволяет построить большие системы с множеством коротких шин и малыми задержками.
Преимущества аппаратной поддержки когерентности проявляются, в частности, в том, что следующий уровень развития - кластерные системы из узлов NUMA-Q могут использовать то же программное обеспечение кластеризации, что и SMP-кластеры с общей шиной.
В качестве среды для передачи данных между узлами NUMA-Q планируется волоконно-оптический канал и программное обеспечение системы Symmetry 5000 (ptx/SDI и Ptx/Clusters). Может возникнуть вопрос, зачем вообще нужно строить кластеры с NUMA-Q-узлами, если вместо этого можно построить очень большие узлы NUMA-Q. Причины те же, из-за которых кластеры применялись и ранее: надежность и масштабируемость. [2]
Одним их ключевых различий описанных архитектур является диктуемая ими модель программирования, а различия в способах программирования напрямую обусловлены задержками доступа. Достижение организации памяти NUMA-Q заключается в том, что доступ к часто используемым данным происходит за микросекунды, тогда как считывание их с диска требует миллисекунд, а в МРР - системах с разделяемыми дисками доступ к удаленному диску может занимать десятки миллисекунд. В кластерах с отражением памяти между узлами добавляются когерентные соединения с программной поддержкой, в результате чего время доступа к удаленной памяти снижается до сотни микросекунд. Это, конечно, в сотни раз быстрее, чем обращаться к дискам для тех же данных, но сотни микросекунд - это все еще в сотни раз медленнее, чем скорость локальной памяти. Поэтому программист должен позаботиться о том, чтобы минимизировать такого типа пересылки, планируя для этого, где только возможно, распределение данных вручную. Следует отметить, что даже в RMC удаленный доступ опирается как на аппаратную, так и на программную поддержку, тогда как доступ к локальной памяти реализуется исключительно аппаратными средствами - очень быстро и с гарантией когерентности. Вот почему программирование в SMP так выгодно для прикладных программистов, которые не должны заботиться о распределении данных в памяти, так как все ее части доступны для любого ЦПУ и доступ к ним одинаково быстр. [2]
В реализации NUMA-Q в этом направлении был сделан еще один шаг. В самом худшем случае время доступа к памяти приблизительно такое же, как в архитектурах с большой шиной. В большинстве же случаев доступ будет в десять раз быстрее. Кроме того, уже 32-процессорная система NUMA-Q будет иметь большую пропускную способность памяти, чем любая другая современная SMP архитектура. Хотя производители "Гига-шины", возлагают большие надежды на шины с 256-битной шириной и пропускной способностью от 1 до 3 Гбайт/с, по-видимому, сейчас это верхний предел. [2]
Архитектура cc-NUMA позволяет создавать легко масштабируемые многопроцессорные системы с небольшими задержками доступа к распределённым в вычислительной системе данным, не требуя для этого заметных модификаций программного обеспечения. Эта архитектура заметно сглаживает нелокальности доступа к данным.
К дополнительным, положительным сторонам данных архитектур можно отнести то, что такие архитектуры как Stanford FLASH требуют незначительных аппаратных затрат и потенциально могут быть очень дешёвыми.
Основными особенностями, которые определяют положительные свойства систем с такой архитектурой, являются